SQL Query Optimization
Improving SQL query performance is crucial for ensuring that your database operations are efficient and scalable. Here are some strategies and tools that can help:
1. Indexing
Indexes are crucial for optimizing database performance, especially for large datasets and complex queries. They provide a mechanism to quickly access data and improve the efficiency of search, sort, and filter operations. Use them on columns that are frequently used in WHERE clauses, JOIN conditions, or as part of an ORDER BY.
Example
Consider a table Employees with columns EmployeeID, LastName, and FirstName.
Without Index
SELECT * FROM Employees WHERE LastName = 'Rohatash';The database engine performs a full table scan, checking each row to see if LastName is "Rohatash". This can be slow if the table has many rows.
With Index
-
Create Index
CREATE INDEX idx_lastname ON Employees(LastName); -
Query with Index
SELECT * FROM Employees WHERE LastName = 'Rohatash';
The database uses the idx_lastname index to quickly locate rows where LastName is "Rohatash". It traverses the index structure rather than scanning the entire table.
The most common type of index used is a B-Tree (Balanced Tree). a B-Tree involves ensuring that all leaf nodes are at the same depth and that the tree maintains its sorted order and structural constraints. Each node in the tree contains a sorted list of keys and pointers to child nodes. The leaf nodes of the B-Tree contain pointers to the actual rows in the table.
Let’s use the string names to build and illustrate a B-Tree of order 3.
We'll use the following names to populate the B-Tree.
- Alice
- Bob
- Charlie
- David
- Eva
- Frank
- Grace
- Helen
Inserting Names in B-Tree
-
Initial Insertions
- Insert Alice, Bob, Charlie: [Alice, Bob, Charlie]
- Insert Alice, Bob, Charlie: [Alice, Bob, Charlie]
-
Inserting David and Eva
- Node splits because it now has 4 keys: [Alice, Bob] [Charlie]
[David, Eva]
- Node splits because it now has 4 keys: [Alice, Bob] [Charlie]
[David, Eva]
-
Insert Remaining Names
- Continue inserting the rest and balancing the tree.
- Continue inserting the rest and balancing the tree.
Here’s the final B-Tree after inserting all names.
[Charlie]
/ \
[Alice, Bob] [David, Eva]
/ | \
[Frank] [Grace] [Helen, Ivy, John]
Explanation
-
Root Node - [Charlie]
This is the top node of the tree and splits the names into three ranges.
-
Child Nodes
- Left Child - [Alice, Bob]
- Contains names less than Charlie.
- Middle Child - [David, Eva]
- Contains names between Charlie and Frank.
- Right Child - [Frank, Grace, Helen, Ivy, John]
- Contains names greater than Charlie.
- Left Child - [Alice, Bob]
2. Query Optimization
- *Avoid SELECT - Specify only the columns you need rather than
using SELECT *, which can reduce the amount of data processed and
transferred.
Example - Consider the query
Instead of SELECT * specify only the columns you need.SELECT * FROM Employees WHERE LastName = 'Rohatash';SELECT EmployeeID, FirstName FROM Employees WHERE LastName = 'Rohatash'; - Use Proper Joins - Ensure that you are using appropriate joins (INNER
JOIN, LEFT JOIN, etc.) and that you are joining on indexed columns.
Example
Using a LEFT JOIN instead of a FULL JOIN when you only need unmatched records from one table can improve performance.
- Analyze Execution Plans - Review
and optimize query execution plans. Use tools like SQL Server Management
Studio (SSMS) to analyze and optimize execution plans.
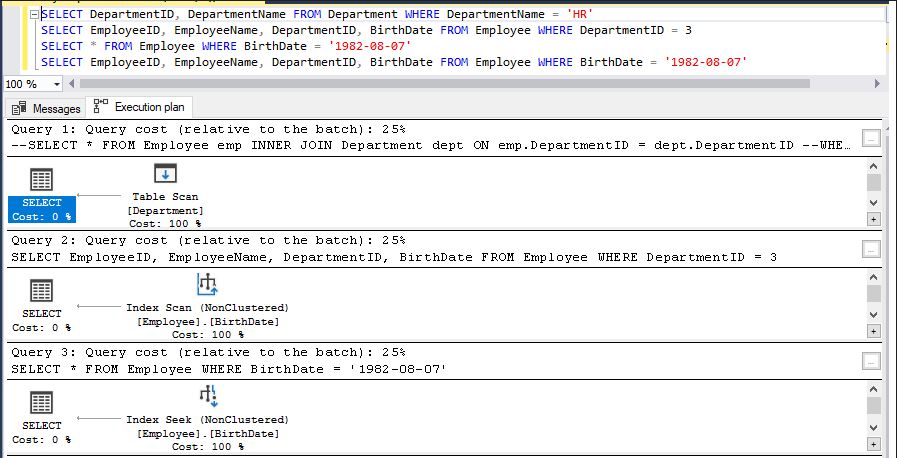
Based on the execution plan image, we have four queries with slight variations. Let's analyze each query individually to identify potential improvements by examining their execution plans.
Here’s a revised explanation for the queries:
Query 1 - The Department table lacks a primary key and clustered index, leading to a full table scan as shown in the execution plan. This is inefficient and slow, especially with a large number of records.
Query 2 - This query performs an index scan, which is somewhat faster than a full table scan since it retrieves data in the sorted order of the clustered index. However, it can still be inefficient and slow when dealing with a large amount of data, as it still scans a significant portion of the table.SELECT DepartmentID, DepartmentName FROM Department WHERE DepartmentName = 'HR'
Query 3 - I created a non-clustered index on the BirthDate column, which can be seen in the execution plan. The included columns are visible in the "Included Columns" tab. This design allows the query to perform an efficient index seek when filtering on BirthDate, especially if many columns are being selected in the SELECT clause.SELECT EmployeeID, EmployeeName, DepartmentID, BirthDate FROM Employee WHERE DepartmentID =3
SELECT * FROM Employee WHERE BirthDate = '1982-08-07'
3. Database Design
- Normalization - Properly normalize your database to eliminate redundant data and ensure data integrity.
- De-normalization - Sometimes de-normalization can improve performance by reducing the number of joins needed, especially in read-heavy databases.
4. Partitioning
- Table Partitioning - Table partitioning in SQL Server is a database design strategy that helps manage large tables by dividing them into smaller, more manageable pieces, called partitions. Each partition can be stored separately, but the table still behaves as a single entity for queries and data operations. This can improve query performance by reducing the amount of data to scan.
Types of Partitioning
- Range Partitioning: The most common form of partitioning in SQL Server, where data is divided into ranges based on the partition key (e.g., date ranges, numeric ranges).
- List Partitioning: Data is partitioned based on a list of values, where each partition holds data that matches one or more specific values.
- Hash Partitioning: SQL Server does not natively support hash partitioning, but similar functionality can be achieved using custom methods.
Range Partitioning
- Improved Query Performance - Queries can be optimized
by accessing only the relevant partitions instead of scanning the entire
table, reducing I/O operations.
How Partitioning Works
Partitioning in SQL Server involves several steps and components:
a. Partition Function
- The partition function defines how the rows in a table are
distributed among the partitions. It specifies the column that will be
used as the partitioning key and the boundary points that divide the
data into partitions.
Example - partitioning a sales table by year would look like this.
This function splits the table into partitions based on year.CREATE PARTITION FUNCTION pfSalesDate (DATE) AS RANGE LEFT FOR VALUES ('2019-12-31', '2020-12-31', '2021-12-31');
b. Partition Scheme
- The partition scheme defines where each partition will be stored. It
maps the partitions created by the partition function to filegroups,
which are physical storage units in SQL Server.
Example
This scheme maps each partition to a different filegroup.CREATE PARTITION SCHEME psSalesDate AS PARTITION pfSalesDate TO (fg1, fg2, fg3, fg4);
- The partition function defines how the rows in a table are
distributed among the partitions. It specifies the column that will be
used as the partitioning key and the boundary points that divide the
data into partitions.
- Once the partition function and partition scheme are defined, you
can create a partitioned table. You assign the table to the partition
scheme, and the data will automatically be partitioned based on the
specified rules.
ExampleCREATE TABLE Sales ( SalesID INT, SaleDate DATE, Amount MONEY ) ON psSalesDate(SaleDate);
c. Creating a Partitioned Table
5. Caching
- Query Caching - SQL caching is a performance optimization technique used to store the results of SQL queries in memory, so that future requests for the same query can be served more quickly without the need to execute the query again on the database. SQL caching can significantly reduce the load on the database and speed up response times, especially for queries that are frequently executed but involve expensive operations like joins, sorting, or aggregations.
Query Result Caching:
- Stores the result set of a query in memory.
- When the same query is executed again, the result is returned from the cache instead of re-executing the query.
- This type of caching is especially useful for read-heavy applications with infrequent data changes.
How SQL Caching Works
Query Result Caching
- Query Execution: The first time a query is executed, the database processes it normally and returns the result.
- Caching the Result: The result is stored in a cache, typically in memory, with a key representing the query (and any parameters).
- Cache Lookup: For subsequent requests, the system checks the cache for a matching key before executing the query. If a match is found, the cached result is returned.
- Cache Expiry: Cached results have a time-to-live (TTL) or are invalidated when the underlying data changes.
Tools and Technologies for SQL Caching
-
In-Memory Caching:
- Redis: An open-source, in-memory data structure store that can be used as a distributed cache.
- Memcached: A general-purpose distributed memory caching system.
6. Tools and Techniques
- SQL Server Management Studio (SSMS) - For SQL Server, SSMS provides tools for analyzing execution plans and query performance.
- EXPLAIN Statement - Most databases support an EXPLAIN statement to provide the query execution plan.
- Database Profiler Tools - Tools like SQL Profiler (for SQL Server), Oracle SQL Trace, or MySQL’s Performance Schema can help identify slow queries and performance issues.
- Query Performance Analyzer - Some databases offer built-in performance analyzers that provide insights into query performance and suggest optimizations.
- Third-Party Tools - Consider third-party performance monitoring tools like SolarWinds Database Performance Analyzer or Redgate SQL Monitor for advanced analytics and recommendations.
7. Maintenance
- Regular Updates - Keep your statistics and indexes up-to-date. Regularly update statistics and rebuild fragmented indexes.
- Database Cleanup - Periodically remove obsolete or redundant data.
8. Configuration
- Database Configuration - Ensure your database server is properly configured for performance, including memory allocation, CPU usage, and disk I/O settings.
Prev Next