SQL Stored Procedure Optimization
Improving SQL Stored Procedure performance is crucial for ensuring that your database operations are efficient and scalable. Here are some strategies that can help:
1. Using SET NOCOUNT ON in Stored Procedures
One simple way to improve the performance of your stored procedures is to add the SET NOCOUNT ON command at the beginning. Normally, SQL Server sends a message every time a command affects a certain number of rows, like "5 rows affected" or "6 rows affected." These messages are not always needed.
If your stored procedure runs many queries or updates, these messages can pile up and create extra network traffic. By using SET NOCOUNT ON, you stop these unnecessary messages, which can help your application run more efficiently, especially if it calls the stored procedure many times.
2. Use Fully Qualified Name
When working with SQL Server, stored procedures are organized into schemas. If you don't specify a schema, the procedure is stored in the default dbo schema. However, it's a best practice to always use the fully qualified name when calling a stored procedure. This means including both the schema name and the procedure name.
Using the fully qualified name helps SQL Server locate and execute the stored procedure more quickly because it doesn't have to search through multiple schemas to find it.
For example, if you have a stored procedure named AllEmployee in the dbo schema, the best practice would be to call it like this.
EXEC dbo.AllEmployee Do not use EXEC AllEmployee. Why? Because by not including the schema, you are making it a little harder for SQL to search through all the database objects to find your stored procedure to run.
3. Avoid Using sp_ Prefix for Stored Procedures
When naming your stored procedures, it's important to avoid starting the name with sp_. Some might think it's a good idea because sp_ seems to stand for stored procedure. However, this prefix is actually reserved by Microsoft for system stored procedures.
If you name your stored procedure with sp_ SQL Server will first search the master database (where system procedures are stored) and potentially other databases before checking your database for the stored procedure. This unnecessary search slows down the execution of your procedure.
To keep things efficient and avoid conflicts, choose a different prefix or naming convention for your stored procedures. This ensures that SQL Server can quickly locate and execute your stored procedure without any unnecessary delays.
4. Avoid Using Cursors
Another important tip for improving the performance of your stored procedures is to avoid using cursors whenever possible. Cursors operate by processing each row one at a time, moving through the result set row by row. This approach can be very slow, especially when dealing with large datasets.
Instead of using cursors, it's better to use set-based queries. SQL is designed to handle sets of data at once, making these operations much faster and more efficient.
A powerful alternative to cursors is to use window functions. Window functions allow you to perform calculations across a set of table rows that are related to the current row, without having to loop through each row individually. For example, you can easily access the previous or next row, calculate running totals, averages, and much more.
In cases where window functions don't fit your needs, you might consider using a recursive common table expression (CTE). Recursive CTEs can replace certain scenarios where you might have used a cursor, particularly when dealing with hierarchical data or performing recursive operations.
The key takeaway is to move away from cursors because they process data row by row, which is inefficient. By using set-based queries, window functions, or recursive CTEs, you can significantly improve the performance of your stored procedures.
5. Use EXISTS instead of COUNT in Sub Queries
Production databases are huge and count() will count all the rows present in the database. exists() on the other hand, stops at the first matching occurrence it finds, saving many other iterations. Sometimes, we need the exact count of rows, but in cases where we need only a true/false (boolean) answer, we can switch to exists(). For example, if we want to find if any candidate who got selected for the job has not been sent an offer letter, we need not get an exact count, but just need to know if any such candidate exists.
6. Query Optimization
- *Avoid SELECT - Specify only the columns you need rather than
using SELECT *, which can reduce the amount of data processed and
transferred.
Example - Consider the query
Instead of SELECT * specify only the columns you need.SELECT * FROM Employees WHERE LastName = 'Rohatash';SELECT EmployeeID, FirstName FROM Employees WHERE LastName = 'Rohatash'; - Use Proper Joins - Ensure that you are using appropriate joins (INNER
JOIN, LEFT JOIN, etc.) and that you are joining on indexed columns.
Example
Using a LEFT JOIN instead of a FULL JOIN when you only need unmatched records from one table can improve performance.
- Analyze Execution Plans - Review
and optimize query execution plans. Use tools like SQL Server Management
Studio (SSMS) to analyze and optimize execution plans.
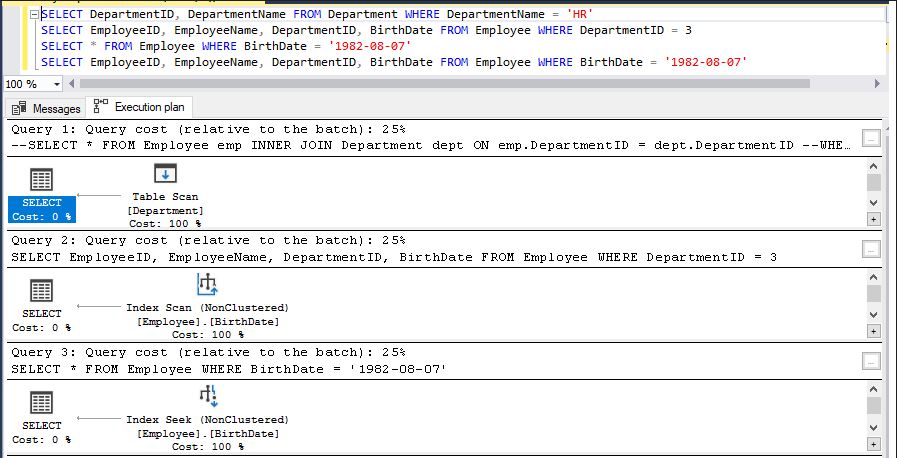
Based on the execution plan image, we have four queries with slight variations. Let's analyze each query individually to identify potential improvements by examining their execution plans.
Here’s a revised explanation for the queries:
Query 1 - The Department table lacks a primary key and clustered index, leading to a full table scan as shown in the execution plan. This is inefficient and slow, especially with a large number of records.
Query 2 - This query performs an index scan, which is somewhat faster than a full table scan since it retrieves data in the sorted order of the clustered index. However, it can still be inefficient and slow when dealing with a large amount of data, as it still scans a significant portion of the table.SELECT DepartmentID, DepartmentName FROM Department WHERE DepartmentName = 'HR'
Query 3 - I created a non-clustered index on the BirthDate column, which can be seen in the execution plan. The included columns are visible in the "Included Columns" tab. This design allows the query to perform an efficient index seek when filtering on BirthDate, especially if many columns are being selected in the SELECT clause.SELECT EmployeeID, EmployeeName, DepartmentID, BirthDate FROM Employee WHERE DepartmentID =3
SELECT * FROM Employee WHERE BirthDate = '1982-08-07'
7. Use Proper Index
Indexes are crucial for optimizing database performance, especially for large datasets and complex queries. They provide a mechanism to quickly access data and improve the efficiency of search, sort, and filter operations. Use them on columns that are frequently used in WHERE clauses, JOIN conditions, or as part of an ORDER BY.
Example
Consider a table Employees with columns EmployeeID, LastName, and FirstName.
Without Index
SELECT * FROM Employees WHERE LastName = 'Rohatash';The database engine performs a full table scan, checking each row to see if LastName is "Rohatash". This can be slow if the table has many rows.
With Index
-
Create Index
CREATE INDEX idx_lastname ON Employees(LastName); -
Query with Index
SELECT * FROM Employees WHERE LastName = 'Rohatash';
The database uses the idx_lastname index to quickly locate rows where LastName is "Rohatash". It traverses the index structure rather than scanning the entire table.
The most common type of index used is a B-Tree (Balanced Tree). a B-Tree involves ensuring that all leaf nodes are at the same depth and that the tree maintains its sorted order and structural constraints. Each node in the tree contains a sorted list of keys and pointers to child nodes. The leaf nodes of the B-Tree contain pointers to the actual rows in the table.
Let’s use the string names to build and illustrate a B-Tree of order 3.
We'll use the following names to populate the B-Tree.
- Alice
- Bob
- Charlie
- David
- Eva
- Frank
- Grace
- Helen
Inserting Names in B-Tree
-
Initial Insertions
- Insert Alice, Bob, Charlie: [Alice, Bob, Charlie]
- Insert Alice, Bob, Charlie: [Alice, Bob, Charlie]
-
Inserting David and Eva
- Node splits because it now has 4 keys: [Alice, Bob] [Charlie]
[David, Eva]
- Node splits because it now has 4 keys: [Alice, Bob] [Charlie]
[David, Eva]
-
Insert Remaining Names
- Continue inserting the rest and balancing the tree.
- Continue inserting the rest and balancing the tree.
Here’s the final B-Tree after inserting all names.
[Charlie]
/ \
[Alice, Bob] [David, Eva]
/ | \
[Frank] [Grace] [Helen, Ivy, John]
Explanation
-
Root Node - [Charlie]
This is the top node of the tree and splits the names into three ranges.
-
Child Nodes
- Left Child - [Alice, Bob]
- Contains names less than Charlie.
- Middle Child - [David, Eva]
- Contains names between Charlie and Frank.
- Right Child - [Frank, Grace, Helen, Ivy, John]
- Contains names greater than Charlie.
- Left Child - [Alice, Bob]
8. Decrease Transaction Scope
When working with transactions in your stored procedures, it's important to keep the transaction scope as small as possible. Transactions are useful for ensuring that multiple related operations—like updating more than one table—are completed successfully together. If one operation fails, the transaction can roll back all the changes, ensuring the data remains consistent.
However, it's crucial not to include unnecessary operations within a transaction. The longer a transaction runs, the longer locks are held on the involved resources. This can lead to increased chances of deadlocks, where two processes are waiting on each other to release locks, causing both to stop.
What is a Deadlock?
A deadlock occurs when two processes are each waiting for the other to release a lock on a resource. For example, Process A is trying to lock a record that Process B has locked, while Process B is trying to lock a record that Process A has locked. Neither can proceed, leading to a situation where both processes are stuck, unable to complete.
How to Avoid Deadlocks
-
Minimize Transaction Scope: Keep the transaction focused only on the necessary operations. Avoid including extra queries, lookups, or non-essential code within the transaction.
-
Get In, Get Out: Ensure that your transaction starts, performs the required updates or inserts, and then immediately commits or rolls back. The faster you complete the transaction, the less time locks are held, reducing the chance of deadlocks.
By decreasing the scope of your transactions, you reduce the time that locks are held, leading to better performance and a lower risk of deadlocks in your database.
9. Avoid Using Scalar Functions in WHERE Clause
Scalar functions in WHERE clauses can prevent the use of indexes. Try to avoid using functions on columns in the WHERE clause, especially if they are applied to each row individually.
10. Avoid Using SELECT INTO
Instead of using SELECT INTO to create a new table, consider creating the table explicitly and then using INSERT. This can be more efficient, especially if the target table already exists.
Prev Next